LLaVA系列:Visual Instruction Tuning
Model对比分析
- LLaVA
- 基于LLaMA-2-7B-Chat, lora 1 epoch
- LLaMA-2-13B-Chat,full_ft 1 epoch
- 基于Vicuna-13B-v1.3,projection 1 epoch, lora 1 epoch,最强
- LLaVA-1.5,基于Vicuna-7B/13B-v1.3,LoRA/full-ft LLM
- LoRA版本能跟full-ft打平手
- LLaVA-NeXT / LLaVA 1.6,
- 全部full-ft LLM
- 基于Vicuna-7B/13B-1.5, Minstral-7B, Hermes-Yi-34B
- 34B模型版本特别强!
LLaVA的核心
data-efficient, 558K for pretrain, 665K for Instruction Tuning
- Pretraining(Alignment)没那么重要,可以轻量级:不需要海量对齐数据,可以冻住LLM只训Connector
- Visual Instruction Tuning很重要
- 可能是因为CLIP Encoder已经在海量数据上对齐了?
简单架构,MLP Connector
切分子图,实现高分辨率:显著降低幻觉!
LLaVA-1.5
LLaVA 1.5 Paper:Improved Baselines with Visual Instruction Tuning
data-efficient, 558K for pretrain, 665K for Instruction Tuning
- Pretraining(Alignment)似乎没那么重要,不需要海量对齐数据,而Visual Instruction Tuning很重要
Abalation
Academic Benchmarks需要short-form answer,而LLaVA在这些benchmark上表现不好。做了如下改进:
Response Formatting prompts+ finetune LLM
- LLaVA在real-world data下效果好,academic benchmark(short answers)上效果不好
- InstructBLIP在academic benchmark上效果好,real-world下效果不好,因为 tends to answer yes for yes/no questions due to the lack of such data in the training distribution
对2023-06-15_InstructBLIP - Towards General-purpose Vision-Language Models with Instruction Tuning的分析:
First, ambiguous prompts on the response format. For example, Q: {Question} A: {Answer}. Such prompts do not clearly indicate the desirable output format.Second, not finetuning the LLM. The first issue is worsened by InstructBLIP only finetuning the Qformer for instruction-tuning. It requires the Qformer’s visual output tokens to control the length of the LLM’s output to be either long-form or short-form, as in prefix tuning [25], but Qformer may lack the capability of properly doing so.
changing Linear Projection to MLP
在LLaVA-Instruct的基础上,加入academic task oriented data
Scaling:
- 把CLIP-ViT-L-224换成CLIP-ViT-L-336
LLaVA
LLaVA paper: Visual Instruction Tuning
核心在于利用Caption&BBox,喂给GPT-4,构造了Visual Instruction-Tuning Data
Instruction Tuning Data
从COCO( images + captions + bounding boxes)构建Instruction-following data
- use GPT-4 or ChatGPT,输入 Captions/Bounding Boxes,输出
- For each type, we first manually design a few examples. They are the only human annotations we have during data collection, and are used as seed examples in in-context-learning to query GPT-4
- 得到LLaVA-Instruct-158K, including 58K in multi-turn conversations, 23K in detailed description, and 77k in complex reasoning
Model
CLIP ViT-L/24, Linear Layer for projection
Training
Alignment on filtered 505K image-text pairs from CC3M, only tune projection layer
- 1 epoch
SFT: projection&LLM with LLaVA-Instruct-158K
- 3 epochs
- 注意:第一轮prompt中,图&文的顺序是随机的!
Eval
LLaVA-Bench(COCO), 90 questions和LLaVA-Bench(In-the-Wild), 24 images with 60 questions
- GPT-4, given textual description(caption) of the image, rates the answer from 1 to 10
Abalations
We tried using the last layer feature from CLIP vision encoder, which yields 89.96% and is 0.96% lower than the feature before the last layer. We hypothesize that this is because CLIP’s last layer features may focus more on global and abstract image properties compared to the layer before it
LLaVA-NeXT / LLaVA-1.6
LLaVA-NeXT(LLaVA 1.6),improved reasoning, OCR, and world knowledge
论文:improved_llava.pdf,3.4节开始是关于LLaVA-1.6的内容
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
- Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
- Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
- Better visual conversation for more scenarios, covering different applications. Better world knowledge and logical reasoning.
Model
It re-uses the pretrained connector of LLaVA-1.5, and still uses less than 1M visual instruction tuning samples. 这一点论文里没说,然而从model zoo看,每个size的model的connector不一样。我理解为由于pretraining阶段的数据集一样,因此第一阶段可以复用同大小model的pretraining。
High-Resolution
切分子图,支持任意分辨率:336 x [(2,2), (1,2), (2,1), (1,3), (3,1), (1,4), (4,1)],论文附录中还支持了1x5,1x6,2x3
Motivation
When provided with high-resolution images and representations that preserve these details, the model’s capacity to perceive intricate details in an image is significantly improved. It reduces the model hallucination that conjectures the imagined visual content when confronted with low-resolution images.
Abalation证明,高分辨率显著降低了Hallucination!
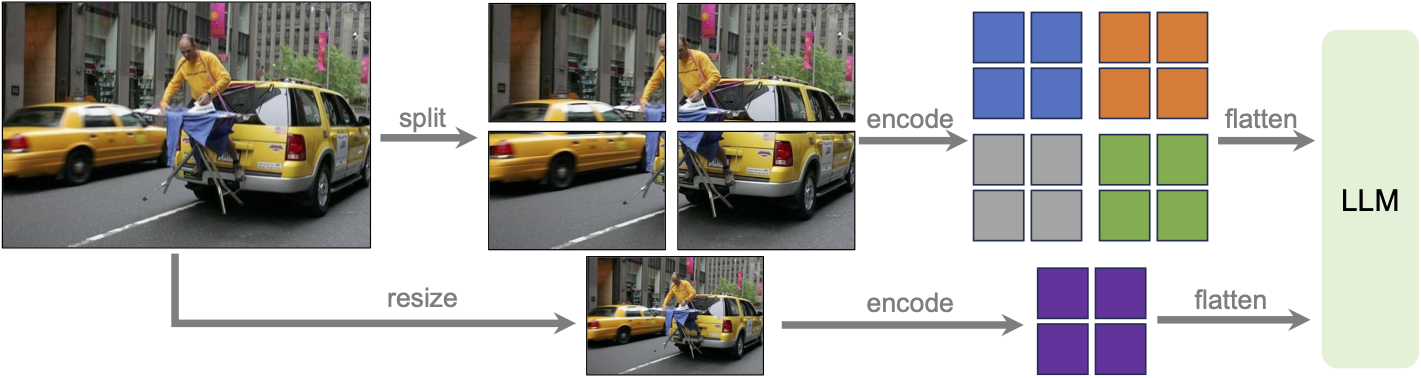
- dividing the image into smaller image patches of the resolution that the vision encoder is originally trained for, and encode them independently.
- After obtaining the feature maps of individual patches, we then combine them into a single large feature map of the target resolution, and feed that into the LLM
同时,pad and resize the image to a single image of 224x224 , and concatenate it with the high resolution features to provide a global context,Ablation证明有用
实现细节:
- predefine a set of resolutions to support up to six grids
- Padding & Padding Removal,避免非方形的输入(需要插值)!
- 换行符,和[Intern-LM-XCompser2-4KHD]一样
Training
第一阶段Alignment Train Connector, 558K
第二阶段 Instruction Tuning Full model, 760K
Ablation
Vicuna-1.5是最强的Base Model,比LLaMA2-Chat强
Data Efficiency:进行data sub-sample之后,仍能有很好的效果,50%的数据也可以有不错的效果
LIMA: less-is-more alignment
通常认为Hallucination来自训练集error,然而,高分辨率显著降低了Hallucination!因此,除了训练集error之外,训练集标注的内容在对应resolution下,无法被模型捕捉到,也可能产生幻觉(相当于模型看不到标注的东西,相当于error)!